
The Truth About Duplicate Content and Its Impact on SEO
Here's the deal—everyone in SEO freaks out about duplicate content as if it's the boogeyman lurking under their website. “Google will penalise you!” “Your rankings will tank!” “Your site will be blacklisted!” Blah, blah, blah.
But here's what nobody tells you: Most of you've heard that duplicate content is outdated, exaggerated, or flat-out wrong. These myths could hold your website back from real growth.
Google isn't out here punishing websites left and right for having similar content. The truth? It's way more nuanced than that. In this article, we'll break down what duplicate content is, how it affects your rankings (spoiler: it's not always bad), and what you should do instead to dominate search results.
- Duplicate content isn't always detrimental; often, it's misunderstood in the SEO community.
- Google doesn't penalise sites for duplicate content unless there's malicious intent.
- Technical SEO is crucial for managing duplicate content and improving indexation.
- Unique, original content is favoured by Google’s algorithms for better rankings.
- Regular audits and tools like Google Search Console are essential for identifying and resolving duplicate issues.
What is Duplicate Content?

Let's start from the beginning and explain carefully what duplicate content entails. Duplicate content refers to content that is either wholly identical or very similar to the original one. When content appears more than once on multiple online sites, such as websites and social media, that is called duplicate content.
There are three different reasons why this sort of content came to be. It was created intentionally and came into existence due to plagiarism or website mismanagement.
As the creator, you purposefully create duplicate content when you use it more than once in several places. You may also come across your content on competing sites; in that case, your content has been plagiarised.
When copies of your content appear more than once on your website, it can be intentional or due to mismanagement. You can intentionally reuse the content as a site owner to extend its value. The other reason duplicate text appears on your website is thanks to boilerplate text.
Boilerplate text copy is often placed on every page of your site, and the problem occurs when the content on each page is ultimately the same. This can cause issues with the site's tags, URLs, etc.
Unfortunately, this leads to search engines getting confused, resulting in wrong pages being returned in search results.
Posting the same content on purpose and plagiarism are examples of external duplicate content, while in the case of website mismanagement, it's considered internal duplicate content.
How Can Duplicate Content Impact SEO?
Duplicate content isn't as harmful as many consider it. However, it can hurt your SEO if you're not careful. The most common harmful impact duplicate content has on SEO is the lack of organic traffic and ranking; you may even lose the SERP presence.
Google can't rank pages that are copied from other sources, and your pages aren't getting indexed. In extreme cases, when duplicate content is used to trick search engines or spam, it can get you penalised or de-indexed.
With that said, you should keep an eye on duplicate content. Try your best to avoid it or, at least, find suitable ways to fix it.
Here are some eye-opening statistics that'll make you sit up and take notice:
- A whopping 29% of pages crawled had duplicate content. That's nearly a third of all web pages, mates. It's like finding out a third of your wardrobe is just copies of the same bloody shirt.
- The average website crawl had 71 pages with duplicate content out of 243 total pages. That's not just a few odd socks in your drawer; it's a full-blown infestation.
- Sites with redirection problems are 72% more likely to have duplicate content. It's like a domino effect of technical cock-ups.
- After the initial post-launch dip, blog posts only reach their true traffic potential around month nine. Most give up before then, leaving potential views on the table.
- AI-generated content is surging by 23%, while traditional formats like white papers are dropping by 12%. The robots are coming for our content, and they're winning.
Now, what does all this mean for the industry? It's a wake-up call, that's what. We're drowning in a sea of sameness, and it's only worsening. The rise of AI is exacerbating the problem, churning out more generic drivel than a politician at election time.
Unique content is becoming the golden ticket. It's like owning a Willy Wonka bar in a world of supermarket chocolates. Google's algorithms are getting smarter, sniffing out originality like a bloodhound.
Websites that offer fresh perspectives and genuine insights are climbing the rankings faster than a squirrel up a tree.
Technical SEO and Duplicate Content
Technical SEO plays a significant role in managing duplicate content. Search engines like Google prioritise efficient crawling, making optimising your site's technical aspects important.
Adjusting URL parameters and robots.txt configurations helps control which pages are indexed. Ensuring that your site is technically sound improves SEO and prevents scenarios where duplicate content might arise due to structural oversights.
Implementing a detailed site audit helps pinpoint technical elements contributing to duplicate content. Regular audits ensure URL structures are consistent, especially with trailing slashes and HTTPS/HTTP preferences.
Using canonical tags effectively becomes part of this audit process, highlighting pages that should be prioritised in indexation. Understanding crawl budget limitations also aids in reducing unnecessary duplicates by ensuring search engine bots focus on the most relevant content.
Myths and Facts about Duplicate Content
There are many myths surrounding duplicate content. That's probably because many find it confusing. However, not all duplicate content is harmful, and most myths are untrue.
To help you better understand duplicate content, we decided to debunk some myths and talk about actual duplicate content facts. Let's start with myths first.
Duplicate content can hurt your search ranking.
The first and most common myth is search ranking and violating Google's guidelines. Can duplicate content hurt your ranking?
The answer is no. Don't worry because Google has explained that if used with positive intent, duplicate content won't affect your search ranking.
You can use quality duplicate content with no keyword stuffing or other lousy SEO practices. And your ranking will be just fine.
However, as we mentioned, mismanaged internal duplicate content can confuse crawlers, and while it won't necessarily affect your ranking, it may link a wrong page with a specific keyword.
Duplicate content can get you penalised.
This myth is closely related to the one above. And like we mentioned, no, Google won't penalise you for duplicate content unless you use it to deceive users and search engines.
If duplicate content purposefully deceives users and is used to manipulate search engines, Google will respond and lower the ranking. For example, Google doesn't even penalise plagiarised content.
Scrapers can hurt your website.
Scrapers are tools used to extract content and data from a website. It sounds awful, but it can't hurt your website. They can't help it either, but there's nothing to worry about regarding web scraping.
Scraper blogs are pretty irrelevant in the eyes of Google, so they can't hurt your rankings, either.
Reposting your guest post to your site is useless.
If you're writing guest posts for other sites, they don't reach your audience. So, republish those guest posts to your website so your audience can read them. No harm, no foul, right?
Technically, yes. Reposting guest content to your site won't hurt your rankings. However, when reposting, be wary of outbound links on guest posts. They can hurt your SEO.
The best would be to change the reposted content slightly so that it is distinguishable from the original one. You can do this by simply adding an HTML label to the post.
Google can find an original content creator.
This is the main problem with plagiarism – Google and other search engines can't tell who the original content creator is.
Anyone can steal your content and call it their own without any penalties. If something like this happens, you contact your lawyers for advice on copyright violations.
Now that we have debunked all the duplicate content-related myths let's discuss facts.
301 redirects can help you avoid duplicate content penalties

Fact number one has to do with a great way to avoid duplicate content penalties. How can you do this? Well, you can redirect old URLs to the new version.
And on which occasions can this be done? These redirects are helpful when you've moved to a new domain, then when you've merged sites and want to redirect outdated URLs, and finally when your home page has several URLs and you want to go back to the original one.
Understanding CMS can also help you avoid duplicate content issues
CMS (content management system) often creates copies without you even knowing. To deal with this, you should try to understand CMS better. Once you get the hang of it, you won't have problems spotting duplicate content.
Role of Content Management Systems (CMS) in Duplicate Content
Content Management Systems like WordPress and Joomla can inadvertently generate duplicate content through default settings.
However, they also offer solutions. WordPress users, for example, can utilise plugins like Yoast SEO to handle canonical tags effectively.
It is beneficial to explore the specific settings of your chosen CMS to enhance your site’s management of duplicate issues, ensuring your content is distinct and well-organised.
Some CMS platforms may inadvertently create archives, tags, or author pages that manifest as duplicate content.
Configuring these options to avoid redundancy is advisable. Advanced users might employ custom scripts or plugins tailored to handle multiple language sites without defaulting to duplicated structures for each version.
Regularly updating CMS software and plugins reduces the likelihood of issues leading to duplicate content.
Minimise boilerplate repetition
Google has some guidelines that can help you deal with boilerplate repetition. But first, let's discuss what boilerplate content is. We already mentioned this type of content and how it can confuse search engines.
For example, copyright notices, disclaimers, and other standardised statements are boilerplate content. When they appear in the text, Google considers them duplicates.
Check Google guidelines to see how to appropriately deal with and minimise boilerplate repetition.
Above, we made a clear distinction between internal and external duplicate content. Now, let's dive deeper and see all the problems with duplicate content and how it impacts SEO.
Internal Duplicate Content Problems

On-page Elements
One way to avoid internal duplicate content problems is by ensuring that each page on your website has a unique title and meta description in the HTML code and headings that are different from other pages on your site.
All three elements are considered minimal content on your web pages. However, paying attention to them is better, so there's no space for duplicate content. Having these elements in order will also allow search engines to see value in your meta descriptions.
In instances when you can't come up with unique meta descriptions, don't write them. In those cases, Google will present certain parts of your content as meta descriptions.
Tools like Google Search Console offer valuable insights into duplicate content. By regularly checking the “Coverage” report, users can identify pages with similar content and address them promptly.
Setting up alerts for URLs labelled as duplicates can ensure you tackle these issues before they affect your search rankings. Bing Webmaster Tools also offers similar functionalities to aid in identifying and rectifying duplicate content effectively.
Making it a habit to check the “HTML improvements” section in Google Search Console regularly can be advantageous. This section highlights possible duplicate titles and meta descriptions, offering a quick overview of potential issues.
Ensuring these details are unique helps reduce duplicate content and improves user experience and click-through rates from search engine results pages. Regularly reviewing these tools can form part of a comprehensive SEO strategy.
URL parameters
Many sites, especially eCommerce sites, have problems with duplicate content thanks to URL parameters. This happens because some websites use URL parameters to create URL variations.
And even the smallest of URL variations can be the cause of duplicate content. These variations originate from analytics code, click tracking, print-friendly versions of pages, or session IDs.
Product descriptions
Creating original descriptions, from meta to product descriptions, is difficult for eCommerce companies. Because it takes much time to write an original description for each product on their website, duplicate content appears on many eCommerce sites.
If you sell your products through third-party retailer websites, ensure you provide the retailer website with a unique product description. If you're struggling with something original, search the internet for helpful tips.
WWW, HTTP, and The Trailing Slash
URLs with and without www, HTTP/HTTPS, and trailing slash at the end of URLs often pose a problem with internal duplicate content; still, everyone keeps forgetting about them.
If you want to see if you're having trouble with your URLs, you can do this by choosing any text from your most valuable loading pages, then putting the quotes on both sides of the text search it on Google.
Once the search is done, you can see if more than one page shows up in the results. If that's the case, you'll need to discover where the problem lies – in www, the lack thereof, HTTP/HTTPS, or the trailing slash creating problems.
If your site has problems with conflicting www or trailing slashes, use the 301 redirects mentioned above.
External Duplicate Content Problems
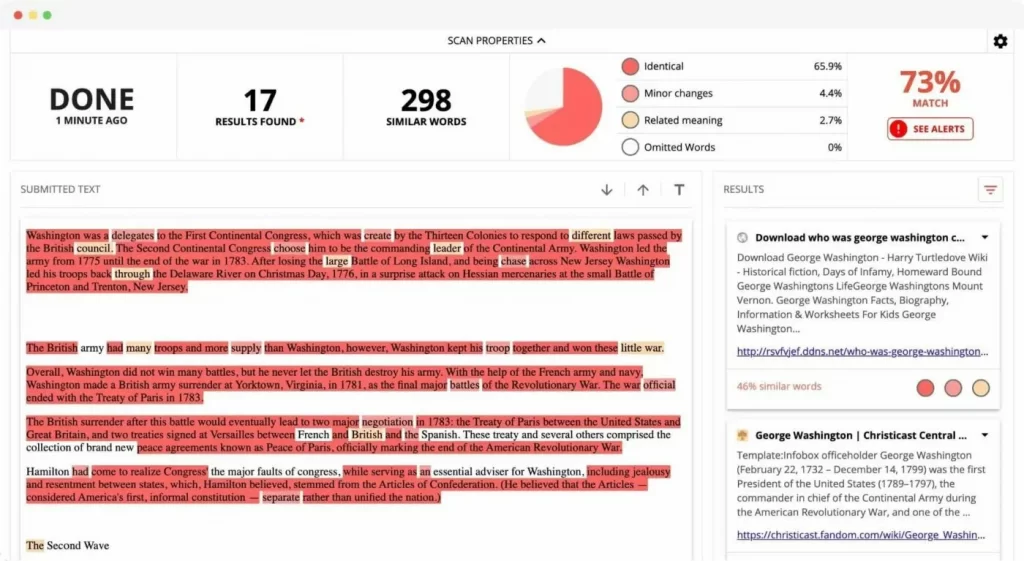
Duplicate content made by content writers
To avoid having duplicate content on your site, you must be careful with whom you work. There are all kinds of content writers – from hard-working ones to those with no qualms about plagiarising other people's work.
When hiring a content writer or team, always ensure that they are reliable and reputable and that their work is top-notch.
On the other hand, if you make a mistake and hire a lousy writer, you risk penalties from Google and, in the worst-case scenario, a lawsuit.
Syndicated content
Republishing content from one site to another is called content syndication. And it's an essential marketing strategy many marketers use. You can see much-syndicated content on LinkedIn, SlideShare, or Quora.
This type of content is used so that you can reach wider audiences (that's one of the reasons why it's a marketing strategy). And yes, syndicated content is technically duplicate, but it's not considered plagiarism or a problem for search engines.
It's not a problem to include a backlink with your syndicated content. If you don't, you'll confuse search engines; they won't know which version is original, which may lead to Google penalising you.
Impact of Social Sharing on Duplicate Content
Sharing content across multiple social media platforms can create the appearance of duplicate content. Customising the accompanying text for each platform helps differentiate these posts.
Using URL shortening services that respect canonical tags ensures that Google recognises these as deliberate shares rather than duplicates. This approach can boost visibility without compromising SEO integrity.
Developing unique shareable content for each social media platform can enhance visibility while reducing duplicate issues. Creating platform-specific fragmented content, such as distinct text descriptions for X, Facebook, or LinkedIn, ensures that each post is recognised as original.
By using UTM parameters and custom URL paths, businesses can track the success of these shares without confusing identical URLs across different social sites.
Scraped content
We touched upon scraped content above. Prevalent sites struggle with their content being scraped and published on other sites. Unlike syndicated content, scraped content can be illegal if it is stolen or used for spam.
The best way to deal with content scraping is by creating as many as possible internal links on your website, using Google alerts, or linking keywords with affiliate links and other similar solutions.
How to Best Deal With Duplicate Content?
Even though you won't get penalised by Google or any other search engine for duplicate content, it still can hurt your rankings. Especially if Google thinks your duplicate content has malicious intent.
So, there are ways to help you avoid duplicate content and, in that way, not risk getting blacklisted by search engines. Here are some of the surefire ways to deal with duplicate content.
Canonicalisation
Canonicalisation is the process of assigning a website a single URL. With a single URL, all other URL versions will be seen as duplicate versions. As duplicate versions, these URLs will be crawled less.
You must tell Google or other search engines which URL is canonical because if you don't, Google will either make a choice for you or decide that both URLs are equal, which can lead to other unwanted issues.
Canonicalisation is vital for all website owners because it can help them promote unique content. The fewer URLs associated with your website, the higher your ranking in search engine result pages. Another benefit is that people can discover your website quickly if it has a single URL.
We also need to clarify that canonicalisation should be performed only once. You don't need to perform it repeatedly if you've already canonised your data. Quite the contrary, if you perform canonicalisation, you can reduce your site's visibility.
So, to sum up, if you implement canonicalisation, your content will remain distinct in search engines and boost your website's visibility and SEO.
Check for lousy duplicate content.
You can easily avoid harmful duplicate content with the help of many different tools. These tools will scan your website for both internal and external duplicate content.
Tools for scanning harmful duplicate content work automatically; if they spot unintentional duplicate content, don't worry; there are ways to deal with it.
You can fix duplicate content by implementing a canonical tag to the original content, using a no-index tag on every duplicate, or completely removing duplicate content – it's up to you.
Using Webmaster Tools for Duplicate Content Identification
Tools like Google Search Console offer valuable insights into duplicate content. By regularly checking the “Coverage” report, users can identify pages with similar content and address them promptly.
Setting up alerts for URLs labelled as duplicates can ensure you tackle these issues before they affect your search rankings. Bing Webmaster Tools also offers similar functionalities to aid in identifying and rectifying duplicate content effectively.
Making it a habit to check the “HTML improvements” section in Google Search Console regularly can be advantageous. This section highlights possible duplicate titles and meta descriptions, offering a quick overview of potential issues.
Ensuring these details are unique helps reduce duplicate content and improves user experience and click-through rates from search engine results pages. Regularly reviewing these tools can form part of a comprehensive SEO strategy.
Use the “noindex” tag.
As mentioned above, you can eliminate duplicate content using the noindex tag. Google can sometimes rank a category or archive over your content. In those cases, you can use the noindex tag to block the indexing of those pages.
Use plagiarism checkers
Like inadequate duplicate content tools, plagiarism checkers scan your text, article, or content containing duplicate information. Plagiarism checker is a must-have for SEO experts, content writers, and pretty much everyone in content marketing agencies.
Combine similar pages
The internet is full of topics that contain similar information. If your website has such issues, they may be seen as duplicates. In these cases, to avoid having duplicate content, you should combine similar information into one post.
Try to avoid using generic page templates to prevent accidentally creating duplicate content. This may confuse your audience and search engine crawlers, as well. If you settle on generic templates, make sure you do much customisation.
Be consistent with internal links.
Duplicate content can be dealt with by building an effective internal linking strategy. This implies that you need to be consistent with internal links. When building internal links to specific pages, always use the same URL.
If you use HTTP in one article, stick with it each time you build an internal link, and don't mix in HTTPS. A single URL for several internal links means linking to the canonical page.
Session ID
A session ID can be best described as a unique number every user gets for their visit to a website.
A Web site's server assigns this number. The point of these sessions is to store users' information for web analytics. However, they can create duplicate content. To avoid this, you should implement self-referencing canonical URLs on pages.
Best Practices for Translation-Related Duplicate Content
When translating content for different regions, hreflang tags become essential. These tags tell search engines which language a page is in, improving visibility in the relevant areas.
Ensuring each version has distinct language tags aids in preventing misinterpretations of duplicate content. Correct implementation of these tags encourages better indexing and improved traffic from targeted geographic locations.
The translation should focus on language, local context, and culture. Ensuring translated content appeals to local audiences while being flagged appropriately using hreflang tags is essential.
When deploying translation services, selecting those proficient in SEO strategies ensures content remains relevant and engages users in the intended regions.
Additionally, when localising content, consider using geo-targeting methods that align with the intended audience's preferences and expectations.
How much duplicate content is ok?
According to SEO experts, some 30% of the internet consists of duplicate content.
Google and other search engines don't clearly define what counts as duplicate content. Still, search engines don't consider duplicate content spam, and you're not at risk of being penalised.
Keep all your content at least 30% different from other copies to be safe. In Google's eyes, duplicate content is everything that contains similar information. So, paraphrasing or replacing words with synonyms is not enough to confuse Google.
Be on top of both your internal and external duplicate content
Duplicate content shouldn't be a problem if you take the time to manage internal duplicate content. As you've read above, dealing with internal duplicate content is possible. It would be best if you kept it to a minimum.
If you keep your internal duplicate content to a minimum, you'll improve the user experience and help search engines index your pages exactly how you want.
External duplicate content can be positive if it's intentional. But to be safe, monitor it regularly.
Conclusion
So, to sum everything up, duplicate content is neither good nor bad. It won't directly hurt your SEO because there are no penalties for duplicate content, except on infrequent occasions.
However, if you're not careful and don't correctly approach duplicate content, it can negatively affect your SEO.
Your website will get less organic traffic because search engines won't know which content is original and won't rank them appropriately. Your website will also have fewer indexed pages because of all the duplicate content.
The best would be to keep a careful eye on duplicate content and avoid it as much as possible. The most frequently used fix for duplicate content is the canonical URL. So, learn as much as you can about the canonicalisation of URLs.


